アウトラインされているイラレ/PDFデータから、70%くらいの正確さではありますが、テキストを抽出する機能が、Acrobatには入ってるんですね!
さすが!
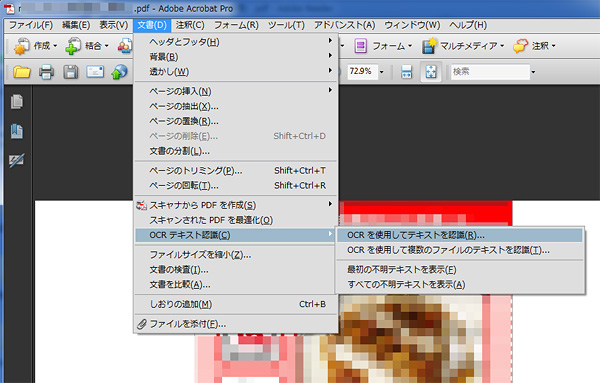
文書>OCRテキスト認識>OCRを使用してテキストを認識
(でも、70%くらいですよ、ほんとに。校正してたら、かなりヤバイ間違いもしますし、手打ちと似たり寄ったりかもしれません。ただ、テキストが膨大な量だったら、助かるかも。)
アウトラインされているイラレ/PDFデータから、70%くらいの正確さではありますが、テキストを抽出する機能が、Acrobatには入ってるんですね!
さすが!
文書>OCRテキスト認識>OCRを使用してテキストを認識
(でも、70%くらいですよ、ほんとに。校正してたら、かなりヤバイ間違いもしますし、手打ちと似たり寄ったりかもしれません。ただ、テキストが膨大な量だったら、助かるかも。)